Group membership models using lmerMultiMember
Ben Bolker, adapted by Phillip Alday
Source:vignettes/group_membership.Rmd
group_membership.RmdGeneral idea
Consider a situation where we have multiple items of some sort which have associated effects, but we can’t association observations with single items; instead, each observation is associated with a group of items. (Two examples which have come up are (1) authorship of papers and (2) hockey players on a team.) These are not quite identical to “multi-membership models” (in part because group membership is binary, i.e., not weighted), although similar techniques to those shown here could work for multi-membership models.
Simple example
Load packages (we don’t really need anything beyond lmerMultiMember; the rest are for convenience/drawing pictures).
library(lmerMultiMember)
library(broom.mixed)
library(ggplot2)
theme_set(theme_bw())
library(Matrix)Construct a simulated example: first, simulate the design (structure).
nm <- 20 # number of groups
nobs <- 1000
set.seed(101)
## choose items for observations
pres <- matrix(rbinom(nobs * nm, prob = 0.25, size = 1), nrow = nobs, ncol = nm)
dimnames(pres) <- list(NULL, LETTERS[seq(nm)])
pres[1:5, ]## A B C D E F G H I J K L M N O P Q R S T
## [1,] 0 0 0 0 1 0 0 0 0 0 1 0 0 1 1 1 1 0 0 0
## [2,] 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 1
## [3,] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1
## [4,] 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1 1 0 0
## [5,] 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0
image(Matrix(pres),
ylim = c(1, 10), sub = "", ylab = "Observation",
xlab = "Item",
## draw tick labels at top
scales = list(at = 1:20, x = list(
labels = colnames(pres),
alternating = 2
))
)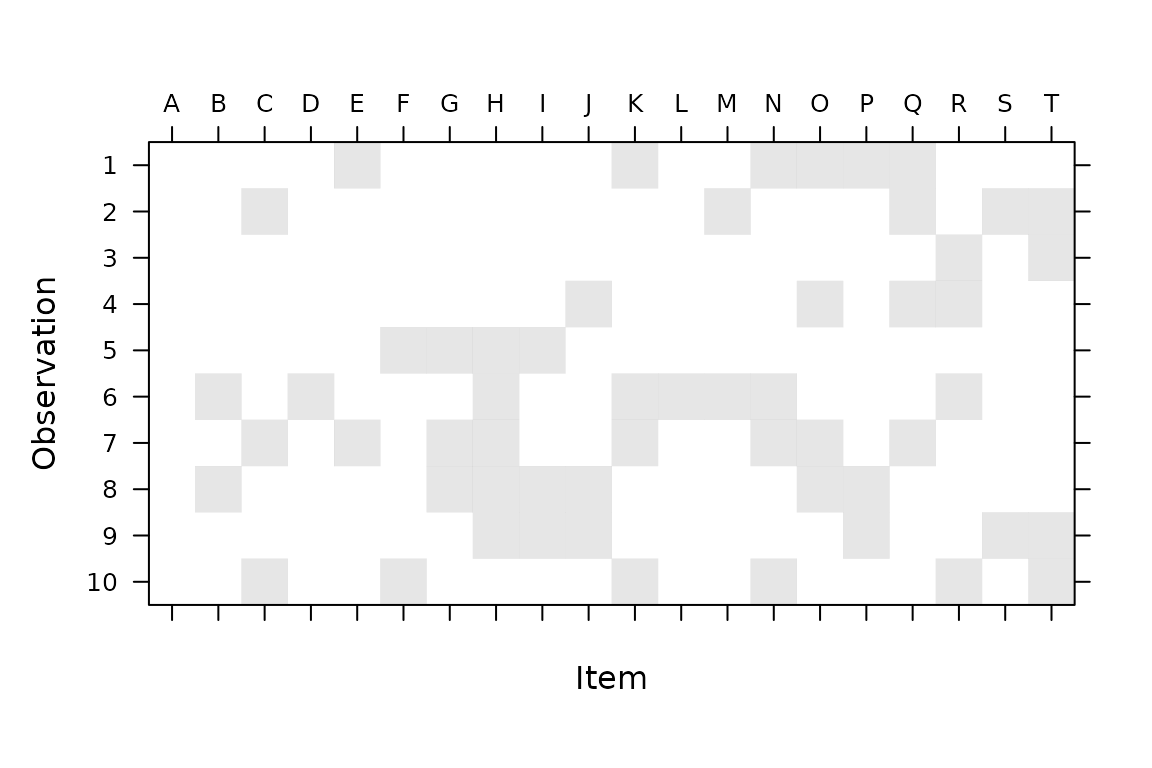
We can look at how many times a particular number of groups occurs (which should match \(Binomial(n=20, 0, p=0.25)\))
hist(rowSums(pres),
main = "Multi-Group Membership",
xlab = "Number of groups associated with an observation"
)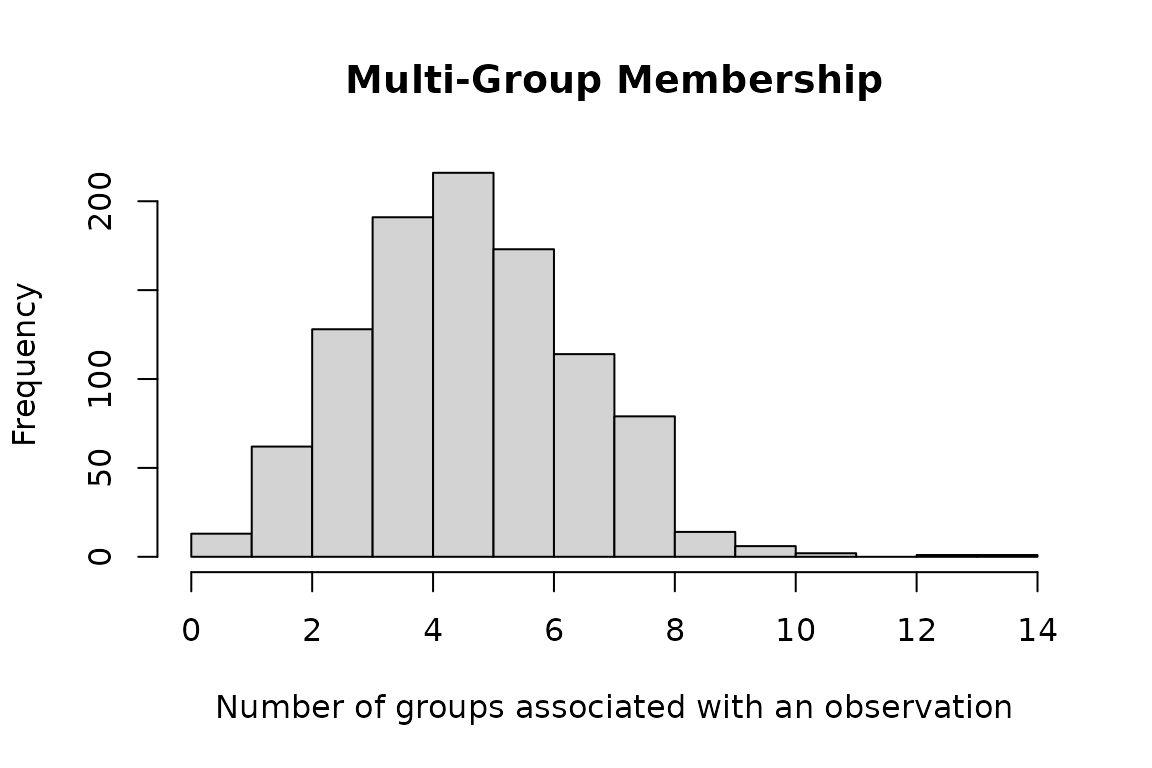
Since we chose which items/individuals to include for each observation randomly and independently (Bernoulli with probability 0.25), we have a highly variable number of individuals present for different observations (1-11). This would be realistic for some examples (authorship), unrealistic for others (hockey) … I don’t think it really makes much difference computationally (statistically, having some observations with a single member must make estimation more powerful …) The 0/1 matrix (indicator variable for whether item \(i\) is included in observation \(j\)) is convenient, and will turn out to be the form we need for inclusion in the model. It should be fairly straightforward to convert other forms (e.g. a list of sets of items associated with each observation) to this form …
Now simulate the response variable.
b <- rnorm(nm, sd = 2) ## item-level effects
## n.b. get in trouble if we don't add residual error
## (theta is scaled relative to residual error)
y <- c(pres %*% b) + rnorm(nobs, sd = 1.5)Fit and the results look OK (correct item and residual variance estimated):
m1 <- lmer(y ~ 1 + (1 | membership),
data = data.frame(y = y, x = rep(1, nobs)),
memberships = list(membership = t(pres))
)
summary(m1)## Linear mixed model fit by REML. Model includes multiple membership random
## effects. [lmerModMultiMember]
## Formula: y ~ 1 + (1 | membership)
## Data: data.frame(y = y, x = rep(1, nobs))
##
## REML criterion at convergence: 3649.6
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.1676 -0.6347 -0.0237 0.6569 3.3445
##
## Random effects:
## Groups Name Variance Std.Dev.
## membership (Intercept) 3.840 1.960
## Residual 1.995 1.412
## Number of obs: 1000, groups: membership, 20
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 0.1618 0.1320 1.226
##
## Group memberships per observation for multiple membership REs:
## Min. per obs. Mean per obs. Max. per obs.
## membership 0 5.067 14The conditional modes by item look good:
dd <- tidy(m1, effects = "ran_vals")
dd <- transform(dd, level = reorder(level, estimate))
truth <- data.frame(level = LETTERS[seq(nm)], estimate = b)
ggplot(dd, aes(x = level, y = estimate)) +
geom_pointrange(aes(
ymin = estimate - 2 * std.error,
ymax = estimate + 2 * std.error
)) +
coord_flip() +
geom_point(data = truth, colour = "red")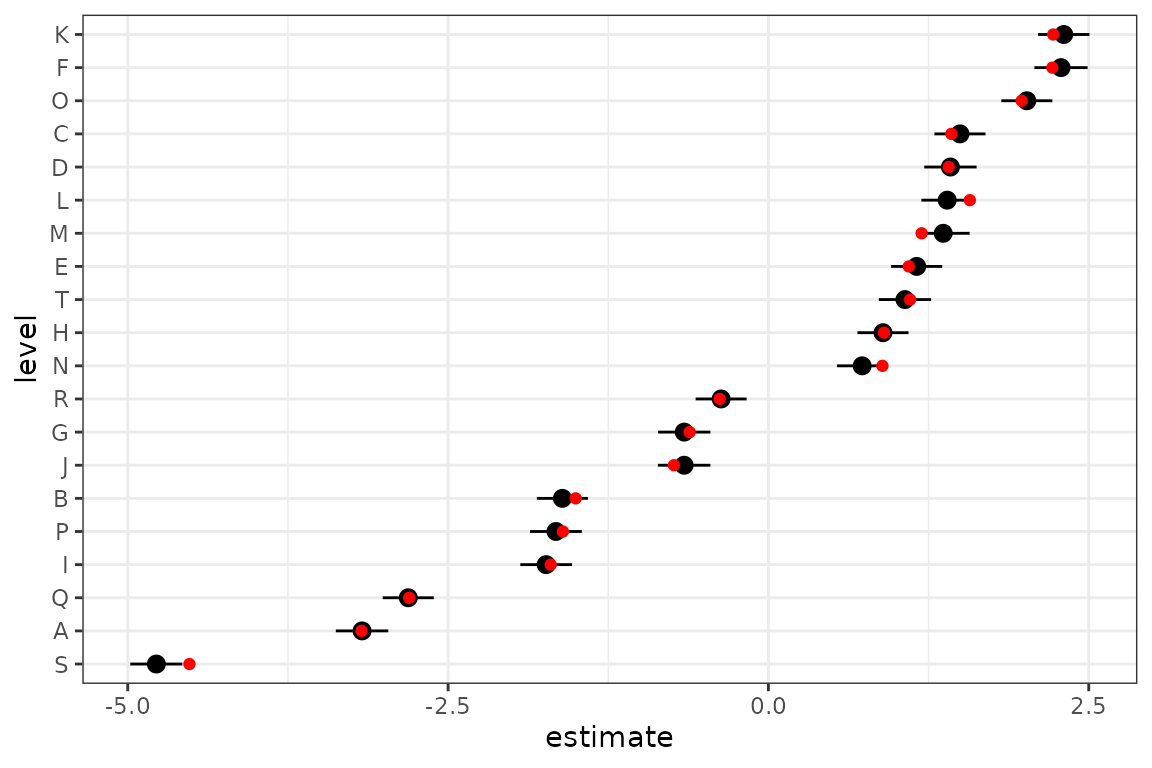
Zooming In: Equal, indepent contributions
Here, we look at a model where each observation is associated with precisely two groups to get a better feel.
set.seed(42)
nobs <- 1000
nm <- 10
dat <- data.frame(
x = runif(nobs),
z = runif(nobs),
# TODO: double check that all(g1 != g2)
g1 = sample(1:nm, nobs, TRUE),
g2 = sample(1:nm, nobs, TRUE)
)
dat$grps <- paste(LETTERS[dat$g1], LETTERS[dat$g2], sep = ",")
# fixed effects
beta <- c(1, 2, 3)
# random effects
bint <- rnorm(nm, sd = 3.14)
# we could be clever about setting the model matrix here, but it's
# easier and clearer how we're constructing bits if we're inefficient
fe <- beta[1] + beta[2] * dat$x + beta[3] * dat$z
# note that the group contributions for each observation are assumed to be
# independent and equally weighted.
# TODO: add example of unequal weights
re <- bint[dat$g1] + bint[dat$g2]
dat$y <- fe + re + rnorm(nobs, sd = 1)
weights <- weights_from_vector(dat$grps)
head(dat)## x z g1 g2 grps y
## 1 0.9148060 0.84829322 2 9 B,I 7.132846
## 2 0.9370754 0.06274633 4 10 D,J -1.199958
## 3 0.2861395 0.81984509 7 4 G,D 1.939330
## 4 0.8304476 0.53936029 3 7 C,G 3.706502
## 5 0.6417455 0.49902010 10 10 J,J -1.075549
## 6 0.5190959 0.02222732 10 9 J,I 1.807260
image(t(weights),
ylim = c(1, 10), sub = "", ylab = "Observation",
xlab = "Item",
## draw tick labels at top
scales = list(at = 1:20, x = list(
labels = colnames(pres),
alternating = 2
))
)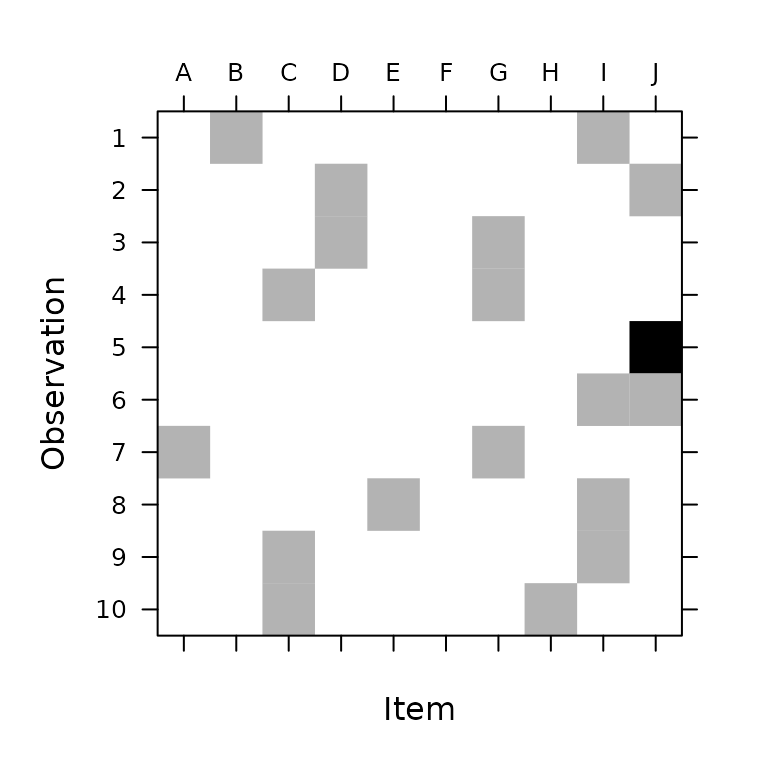
m2 <- lmer(y ~ 1 + x + z + (1 | g),
data = dat,
memberships = list(g = weights), REML = FALSE
)
summary(m2)## Linear mixed model fit by maximum likelihood . Model includes multiple
## membership random effects. [lmerModMultiMember]
## Formula: y ~ 1 + x + z + (1 | g)
## Data: dat
##
## AIC BIC logLik deviance df.resid
## 2985.4 3009.9 -1487.7 2975.4 995
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.94604 -0.65151 0.00031 0.66380 3.15347
##
## Random effects:
## Groups Name Variance Std.Dev.
## g (Intercept) 12.644 3.556
## Residual 1.061 1.030
## Number of obs: 1000, groups: g, 10
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) -1.2482 2.2505 -0.555
## x 1.8539 0.1125 16.474
## z 2.9098 0.1106 26.307
##
## Correlation of Fixed Effects:
## (Intr) x
## x -0.024
## z -0.024 -0.001
##
## Group memberships per observation for multiple membership REs:
## Min. per obs. Mean per obs. Max. per obs.
## g 2 2 2Not ideal, but not horrible – it looks like there is an upward bias, but this is inline with the estimate for the group standard deviation being a bit off.
dd <- tidy(m2, effects = "ran_vals")
dd <- transform(dd, level = reorder(level, estimate))
truth <- data.frame(level = LETTERS[seq(nm)], estimate = bint)
ggplot(dd, aes(x = level, y = estimate)) +
geom_pointrange(aes(
ymin = estimate - 2 * std.error,
ymax = estimate + 2 * std.error
)) +
coord_flip() +
geom_point(data = truth, colour = "red")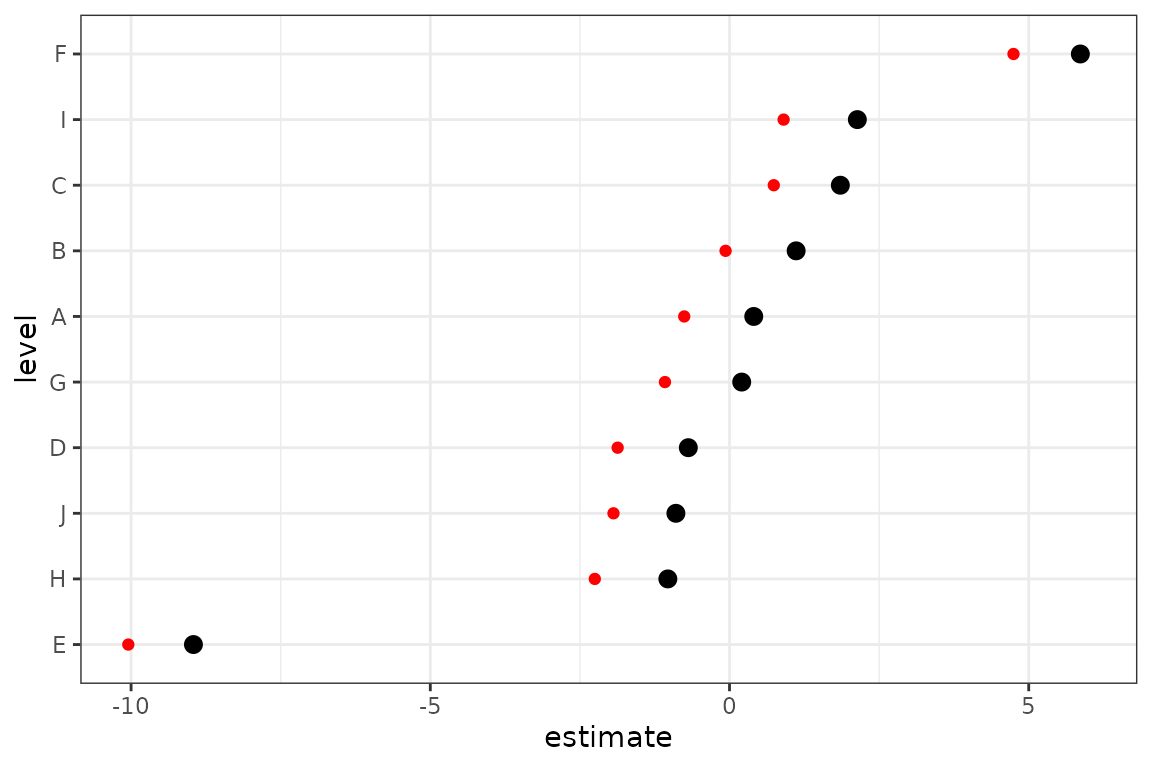
A slightly more complex example
Here we build on our last example by adding a random slope.
set.seed(42)
nobs <- 10000
nm <- 26
dat <- data.frame(
x = runif(nobs),
z = runif(nobs),
# TODO: double check that all(g1 != g2)
g1 = sample(1:nm, nobs, TRUE),
g2 = sample(1:nm, nobs, TRUE)
)
dat$grps <- paste(LETTERS[dat$g1], LETTERS[dat$g2], sep = ",")
# fixed effects
beta <- c(1, 2, 3)
# random effects
bint <- rnorm(nm, sd = 3.14)
bx <- rnorm(nm, sd = 0.2)
# we could be clever about setting the model matrix here, but it's
# easier and clearer how we're constructing bits if we're inefficient
fe <- beta[1] + beta[2] * dat$x + beta[3] * dat$z
# note that the group contributions for each observation are assumed to be
# independent and equally weighted.
# TODO: add example of unequal weights
re <- bint[dat$g1] + bint[dat$g2] + (bx[dat$g1] + bx[dat$g2]) * dat$x
dat$y <- fe + re + rnorm(nobs, sd = 1)
head(dat)## x z g1 g2 grps y
## 1 0.9148060 0.5283896 11 13 K,M 9.7194660
## 2 0.9370754 0.6463879 24 12 X,L 4.9175119
## 3 0.2861395 0.8340490 17 2 Q,B 0.3754283
## 4 0.8304476 0.3457626 22 19 V,S 8.4488474
## 5 0.6417455 0.6217329 25 20 Y,T 5.8487113
## 6 0.5190959 0.6631953 23 10 W,J 9.5083034
image(t(weights_from_vector(dat$grps)),
ylim = c(1, 10), sub = "", ylab = "Observation",
xlab = "Item",
## draw tick labels at top
scales = list(at = 1:20, x = list(
labels = colnames(pres),
alternating = 2
))
)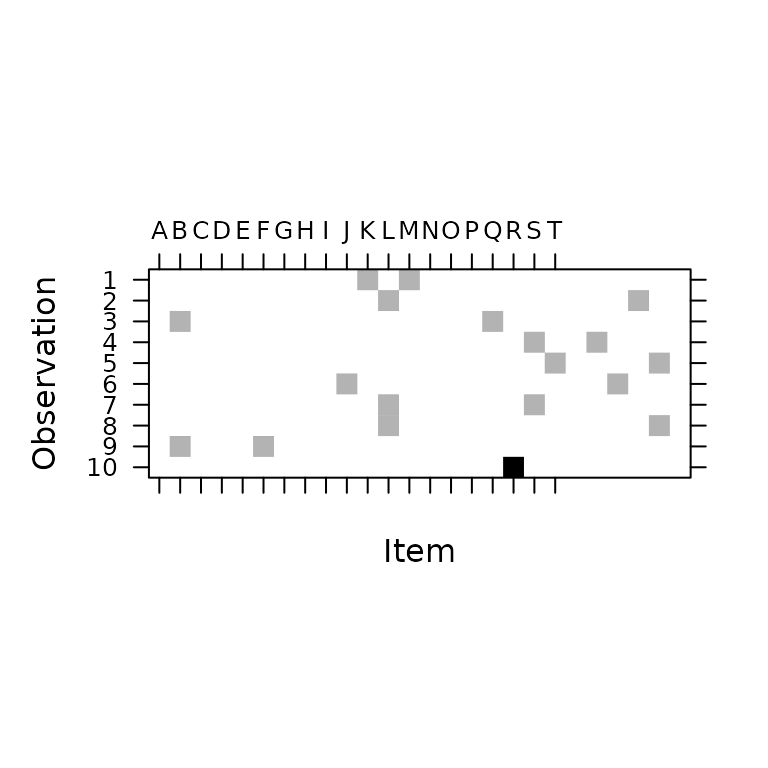
m3 <- lmer(y ~ 1 + x + z + (1 + x | g),
data = dat, REML = FALSE,
memberships = list(g = weights_from_vector(dat$grps))
)
summary(m3)## Linear mixed model fit by maximum likelihood . Model includes multiple
## membership random effects. [lmerModMultiMember]
## Formula: y ~ 1 + x + z + (1 + x | g)
## Data: dat
##
## AIC BIC logLik deviance df.resid
## 28687.9 28738.4 -14337.0 28673.9 9993
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.5911 -0.6717 -0.0054 0.6643 3.8577
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## g (Intercept) 9.8809 3.1434
## x 0.0354 0.1882 0.01
## Residual 1.0031 1.0015
## Number of obs: 10000, groups: g, 26
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 3.12330 1.23322 2.533
## x 2.08221 0.08148 25.553
## z 3.01460 0.03466 86.967
##
## Correlation of Fixed Effects:
## (Intr) x
## x 0.005
## z -0.014 0.000
##
## Group memberships per observation for multiple membership REs:
## Min. per obs. Mean per obs. Max. per obs.
## g 2 2 2
dd <- tidy(m3, effects = "ran_vals")
dd <- transform(dd, level = reorder(level, estimate))
truth <- rbind(
data.frame(level = LETTERS[seq(nm)], estimate = bint, term = "(Intercept)"),
data.frame(level = LETTERS[seq(nm)], estimate = bx, term = "x")
)
ggplot(dd, aes(x = level, y = estimate)) +
geom_pointrange(aes(
ymin = estimate - 2 * std.error,
ymax = estimate + 2 * std.error
)) +
coord_flip() +
geom_point(data = truth, colour = "red") +
facet_wrap(~term)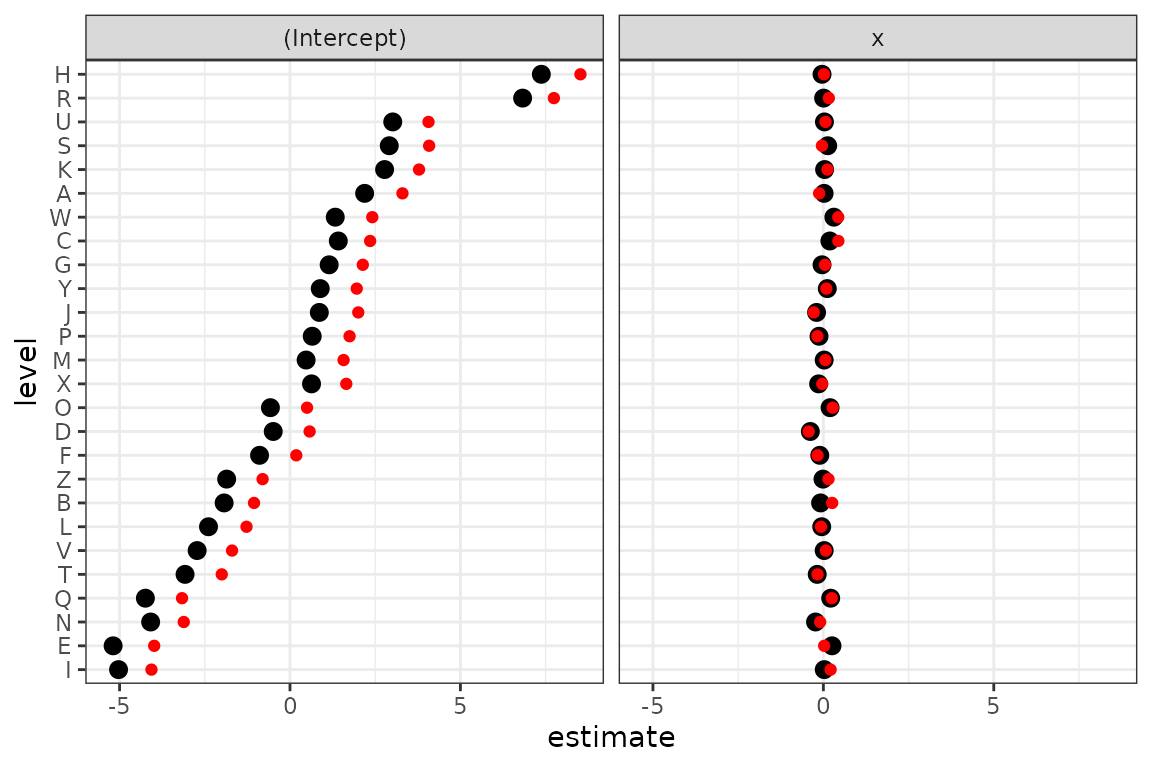
# note that we have a random slope for which we didn't introduce any variation
# in the data, which is the same as setting it to zero
m4 <- lmer(y ~ 1 + x + z + (1 + x + z | g),
data = dat, REML = FALSE,
memberships = list(g = weights_from_vector(dat$grps))
)
summary(m4)## Linear mixed model fit by maximum likelihood . Model includes multiple
## membership random effects. [lmerModMultiMember]
## Formula: y ~ 1 + x + z + (1 + x + z | g)
## Data: dat
##
## AIC BIC logLik deviance df.resid
## 28693.5 28765.6 -14336.7 28673.5 9990
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.5946 -0.6727 -0.0037 0.6656 3.8513
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## g (Intercept) 9.9323317 3.15156
## x 0.0354297 0.18823 0.01
## z 0.0002575 0.01605 -1.00 0.01
## Residual 1.0030416 1.00152
## Number of obs: 10000, groups: g, 26
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 3.12317 1.23642 2.526
## x 2.08243 0.08151 25.548
## z 3.01462 0.03523 85.570
##
## Correlation of Fixed Effects:
## (Intr) x
## x 0.004
## z -0.192 0.002
##
## Group memberships per observation for multiple membership REs:
## Min. per obs. Mean per obs. Max. per obs.
## g 2 2 2
# note that we have a random slope for which we didn't introduce any variation
# in the data, which is the same as setting it to zero
m4zc <- lmer(y ~ 1 + x + z + (1 + x + z || g),
data = dat, REML = FALSE,
memberships = list(g = weights_from_vector(dat$grps))
)
summary(m4zc)## Linear mixed model fit by maximum likelihood . Model includes multiple
## membership random effects. [lmerModMultiMember]
## Formula: y ~ 1 + x + z + (1 + x + z || g)
## Data: dat
##
## AIC BIC logLik deviance df.resid
## 28687.9 28738.4 -14337.0 28673.9 9993
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.5912 -0.6718 -0.0054 0.6645 3.8579
##
## Random effects:
## Groups Name Variance Std.Dev.
## g (Intercept) 9.88344 3.1438
## g.1 x 0.03541 0.1882
## g.2 z 0.00000 0.0000
## Residual 1.00309 1.0015
## Number of obs: 10000, groups: g, 26
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 3.12330 1.23338 2.532
## x 2.08221 0.08149 25.550
## z 3.01461 0.03466 86.967
##
## Correlation of Fixed Effects:
## (Intr) x
## x -0.006
## z -0.014 0.000
##
## Group memberships per observation for multiple membership REs:
## Min. per obs. Mean per obs. Max. per obs.
## g 2 2 2Session info:
## R version 4.3.1 (2023-06-16)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 22.04.3 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] Matrix_1.5-4.1 ggplot2_3.4.4 broom.mixed_0.2.9.4
## [4] lmerMultiMember_0.11.8
##
## loaded via a namespace (and not attached):
## [1] future_1.33.0 sass_0.4.7 utf8_1.2.3 generics_0.1.3
## [5] tidyr_1.3.0 stringi_1.7.12 lattice_0.21-8 listenv_0.9.0
## [9] lme4_1.1-34 digest_0.6.33 magrittr_2.0.3 evaluate_0.22
## [13] grid_4.3.1 fastmap_1.1.1 rprojroot_2.0.3 jsonlite_1.8.7
## [17] backports_1.4.1 purrr_1.0.2 fansi_1.0.5 scales_1.2.1
## [21] codetools_0.2-19 textshaping_0.3.7 jquerylib_0.1.4 cli_3.6.1
## [25] rlang_1.1.1 parallelly_1.36.0 munsell_0.5.0 splines_4.3.1
## [29] withr_2.5.1 cachem_1.0.8 yaml_2.3.7 parallel_4.3.1
## [33] tools_4.3.1 memoise_2.0.1 nloptr_2.0.3 minqa_1.2.6
## [37] dplyr_1.1.3 colorspace_2.1-0 forcats_1.0.0 globals_0.16.2
## [41] boot_1.3-28.1 broom_1.0.5 vctrs_0.6.4 R6_2.5.1
## [45] lifecycle_1.0.3 stringr_1.5.0 fs_1.6.3 MASS_7.3-60
## [49] furrr_0.3.1 ragg_1.2.6 pkgconfig_2.0.3 desc_1.4.2
## [53] gtable_0.3.4 pkgdown_2.0.7 bslib_0.5.1 pillar_1.9.0
## [57] glue_1.6.2 Rcpp_1.0.11 systemfonts_1.0.5 xfun_0.40
## [61] tibble_3.2.1 tidyselect_1.2.0 knitr_1.44 farver_2.1.1
## [65] htmltools_0.5.6.1 nlme_3.1-162 labeling_0.4.3 rmarkdown_2.25
## [69] compiler_4.3.1